Sometimes you just want to know which pages of your website Google have within their huge index of URLs. Perhaps you need this information for a site migration to ensure all those important redirects are handled correctly. Perhaps you need the data as a crucial part of a technical website audit to check for signs of duplication or repetition. Or perhaps there’s another reason or you’re just curious! Whatever the reason this seemingly simple task of obtaining a list of URLs indexed by Google is challenging.
You may think that crawling the website with spider software such Xenu or Screaming Frog will give you a list of all available URLs but this only provides a list of all links accessible from within the website itself; not a list of all pages indexed by Google.
You would have thought Google could just provide the list but for whatever reason they do not currently share this information. Google Webmaster Tools (and Bing Webmaster Tools for that matter!) contains a feature which allows the webmaster to see the number of pages indexed but does not provide an option to export the list. Hopefully one day they’ll add this feature, but in the meantime you’ll have to resort to other methods.
I’m going to show you how you can extract a list of all URLs available from Google in 6 easy steps without scraping Google SERPs with automated tools or having the mundane task of manually copying and pasting each URL from a ‘site:’ search.
Disclaimer:Some may argue that this tutorial itself is a method of scraping Google search results, which I guess it kind of is; but in my mind methods of scraping often lean towards automated tools with malicious intent. What we’re going to do is not intended for malicious purposes, in fact it’s quite the opposite as it’ll help you, the webmaster, to understand which pages are indexed by Google and act accordingly. Plus if Google were to just provide this data we wouldn’t have to resort to these techniques!
SERP Link Extraction
The process is very simple - we’re going to use the “site:” search operator to produce a list of URLs indexed within your domain and use a JavaScript based tool to extract the URL data from the source code. Simple hey - and not at all malicious!
You’re going to need to use Google Chrome to do this as you’ll need to install a Chrome extension.
Ready? Let’s go!
- Perform your site search - for example site:highposition.com
- Modify the number of results returned for your site search queryBy default, Google limit the number of search results to 10 per page so depending on the size of your site we’re going to need to increase this to 100 per page.Arguably we could proceed with 10 results per page instead of 100 but that approach will increase the query depth thus increasing the number of requests made to Google.To increase the number of results per page, click the Gear icon within the search results page and click ‘Search Settings’:
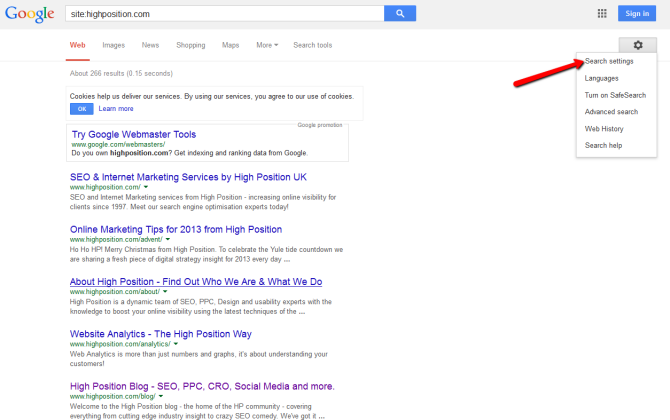 Scroll down to ‘Google Instant predictions’, check ‘Never show Instant Results’ and increase the ‘Results per Page’ to 100:Make sure these settings are saved.
Scroll down to ‘Google Instant predictions’, check ‘Never show Instant Results’ and increase the ‘Results per Page’ to 100:Make sure these settings are saved. - Next we’re going to use a Chrome extension called gInfinity to remove the 100 results per page limit by seamlessly merging groups of SERPS into a single list.Head over to Chrome Web Store, download and install the extension.
- Go back to your list of the first 100 search results for your “site:” search query. Scroll down to the bottom of the page and watch as gInfinity automatically queries the next batch of results, displaying them all on a single page.
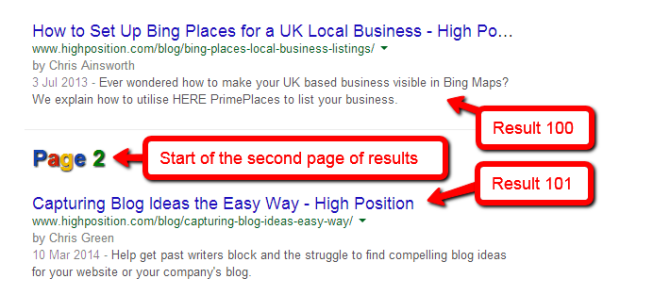 Loop through this step until you have all URLs list on a single page.NOTE: If you’ve got a large website of 100,000’s of URLs you might want to be a little cautious here. We’re querying Google multiple times using gInfinity to render the data accordingly. The more data you query, the more Google gets suspicious, thus this isn’t exactly a Google friendly way of obtaining the list. That said, the worst Google will do is check that you’re a human through CAPTCHA validation.Also, you don’t necessarily have to extract all the data in a single hit. You could query 100 pages, extract the data, do the next 100 at a later date and so forth, amalgamating the data as you go. I prefer this method because it’s quick but the decision is yours!
Loop through this step until you have all URLs list on a single page.NOTE: If you’ve got a large website of 100,000’s of URLs you might want to be a little cautious here. We’re querying Google multiple times using gInfinity to render the data accordingly. The more data you query, the more Google gets suspicious, thus this isn’t exactly a Google friendly way of obtaining the list. That said, the worst Google will do is check that you’re a human through CAPTCHA validation.Also, you don’t necessarily have to extract all the data in a single hit. You could query 100 pages, extract the data, do the next 100 at a later date and so forth, amalgamating the data as you go. I prefer this method because it’s quick but the decision is yours! - Now for the clever bit. Once you’ve got your list of URLs (however many that may be) you need to extract the data.
Drag and drop this bookmarklet into your ‘Bookmarks’ toolbar:
SERP%20Link%20Generator |
| ID | Link | Anchor | ';for(i=0;i
|---|---|---|
| '+linkcount+' | ';output+=''+pageAnchors[i].href+' | ';output+=''+anchorText+' | ';output+='
URL%20List
Anchor%20Text%20List
%C2%A0
Make sure you have the Google SERPS in front of you, and click the bookmarklet:

A new window will then open listing all of the URLs and anchor texts:
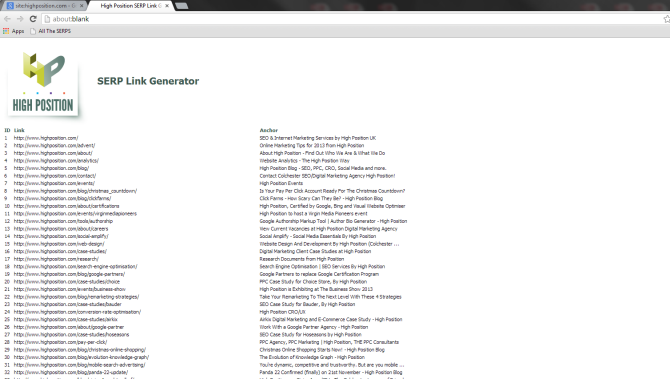
- Now you can copy and paste the data and do with it what you wish.
That’s it! Six easy steps to obtain a list of all URLs indexed by Google. The bookmarlet includes three sets of data:
- Link and anchor table
- A complete URL list
- A complete anchor text list
You don’t necessarily have to use this for search results either. This tool can potentially extract link data from any given page as it’s essentially just a manipulation of a webpage’s source code.
For other useful bookmarlets check out this list of bookmarklets by High Position’s Head of Search, Tom Jepson, published last year. There are some great tools there, so be sure to check them out and let us know if you have any suggestions.
Finally, it would also be highly inappropriate if I didn’t give credit where credit is due to Liam Delahunty of Online Sales as my bookmarlet is a modified version of the original code by Liam customised to extract SERPs. Be sure to check out the other tools by Liam.
Update: 15th October 2014
I thought it would be worth mentioning that with Google continually tweaking the way in which search results are displayed, this bookmarklet will often require updating to the reflect the changes within Google’s code. I have just updated the bookmarklet to ignore the autogenerated inline sitelinks.
Extract URLs from Google Image Search
For those who found this tool useful I have recently (January 2015) published a new tool for extracting URLs from Google’s Image search. Enjoy! 




Hi Chris…. I cannot get past the 700 url mark… when there are over 3,000 listed in site:www.etc
Hi Neil.
This technique will only ever return a list of URLs that Google serves - beyond that there’s no hope!
Assuming your talking about lastminutetheatretickets.com it looks like there a large proportion of URLs from your domain may have been omitted from site: search results. Even when seemingly including omitted results the number of URLs returned still varies from Google’s estimated number of URLs indexed.
That said, Google “About x,xxx results (x.xx seconds)” is often misleading - I’d always use Google Webmaster Tools’ index statistics as this is generally far more accurate.
Anyway back to the problem. It looks like Google has a lot of old, redundant URLs indexed, most of which contain ‘index.php’, for example lastminutetheatretickets.com/londonwestend/index.php/49846/theatre-news-tuesday-17th-december-2013/ which now redirects.
As well as old URLs which 301 redirect then return a 404 Not Found status, for example lastminutetheatretickets.com/londonwestend/index.php/49975/ten-of-the-most-talented-london-west-end-men/sb1/
As an educated guess I would say Google isn’t returning the full set of URLs within the site: search as they’re redundant and therefore now irrelevant.
You’ll probably find that Google has began dropping URLs where 301s or 404s are in effect but the estimated number of indexed URLs does not yet reflect this.
I would recommend reviewing the number of pages indexed through Webmaster Tools and looking at the index stats to see if there has been any recent change?
Hope that helps!
Chris
i found a bug if you use it, no matter what domain first row in a report will be youtube.com where is came from lol why youtube?
Hi Stan,
Thanks for the heads up. If you try it now it should work.
It’s difficult to strip all of the links which Google’s interface contains be default. In this particular instance the youtube.com link came from the Google services/apps list; they’d changed an ID which the script didn’t handle.
It’s certainly not perfect, but it’s a start
Chris
Hi Chris
Thank you very, very much for this tutorial !
Immensely helpful for finding duplicate pages that were indexed for my website.
Without your help, the task would have been practically too complicated to achieve.
Cheers
Derek.
No problem. Glad to be of service
Hey Chris -
Thanks for the great tool that even a beginner like me can understand. One question: Since I don’t want to get banned by Google, how is it possible to harvest URLs in “batches” using this method? You mentioned that you could harvest 100 now, and the next 100 another time, etc. Each time I run my query, I should get approximately the same results. If I have ginfinity in place, I scroll down and it immediately begins to accumulate the blocks of 100 results, separating them with a page number. Let’s say I harvest the first 4 pages, and then I want to go back and begin harvesting pages 5 through 8. How do I do that?
Any help you can provide would be sincerely appreciated!
Kim
Hi Kim,
You can’t really do that if you’re using gInfinity (without it getting messy!). The only way to do it would be to remove/disable gInfinity and harvest 100 URLs at a time i.e. page 1 (results 1-100), page 2 (results 101-200), etc.
Also I think it’s worth clarifying that you won’t get “banned” by Google for taking this approach. We’re not making malicious attempts to scrape search results, we’re merely using the ‘site:’ search function to our advantage.
The worst that will happen is that you’ll trigger a CAPTCHA code for excessive querying of Google and to identify that your human, not a scraper.
Unless your doing this regularly, and on a huge scale, I wouldn’t lose sleep over it
Chris
Wayyyyyy too complicated. Want the easy way?
1) Copy all the text on the result page into a text tile
2) Open an Excel spreadsheet
3) Import the text file into the sheet
4) Sort on commas or spaces, take your pick
5) Sort on the first column
6) Delete all the other columns and unwanted rows
Bada-bing, bada-boom. Ten seconds tops. No danger of ticking off Google.
Hi Stefanie,
Many thanks for your comment, I’m always keen to hear other people’s opinions/approaches.
The route which you have suggested is certainly one option, but is that really the easier option?
1. For starters it involved more manual effort which is often more prone to error, especially for those who are unfamiliar with software such as Excel.
2. You’ll only be able to handle a max of 100 URLs at a time, which is fine for smaller sites but not for let’s say a large scale e-commerce platform.
3. And you’ll have to sort/filter the data to remove the unwanted data such as Titles and Meta Descriptions. It seems like an awfully long-winded approach to me.
Moreover your approach may not provide the desired results. If your website utilises a lengthy URL structure whereby URLs are truncated within search results (such as yourdomain.co.uk/sub-folder/…/blue-widgets.php) then your approach will only provide the truncated URL, not the full destination URL; therefore you approach will fail to provide the correct URL(s).
The approach which I have documented is all about accuracy and scalability with minimal manual effort.
If you’re working with a small number of concise URLs then your solution may be feasible, but it’s not scalable. If you’re working with a large number of complex URLs then my approach offers a better solution in my opinion, but do whatever works best for you
Chris
You got me on the truncated URLS - but I found a workaround that fixed it for my site. By sorting the URLS I was able to select one URL for each folder, find the correct missing middle path portion, and “find and replace”. Yes, I’m only working with a smallish (about 2,000 pages) site, but it still only took me about an hour to accomplish the whole task. I didn’t have any issues with the titles and meta descriptions that you mentioned - they filtered out right off the bat.
I just created one large text file of all the results, copying in the results in batches of 100. I did not go through the entire process for each separate batch of 100.
I will admit I’m very well-versed in Excel, so yes, it may be trickier for someone that’s not. But if you are working with a smaller site, and are comfortable with it, I do think this merits a shot. If I ever have to strip URLs from a large site, I’ve bookmarked your method
Great help Chris !
Thanks a lot…
But i was able to fetch only around 430 URL’s from 1990 indexed pages ….
May be that’s all what would be indexed by Google.
But it really helped !
Thanks
This is brilliant - just what I’ve been looking for today. Thanks - I’ve also combined it with some code I found on Github to let you mass submit URLs into the Google WMT for mass removals… which was my actual end plan - thanks!
Marc, what’s the tool you found to mass remove URLs?
Just working on combining 5 ecommerce websites into 1 and needed a good way to extract indexed links from all 5 sites. Pefect, thanks Chris!
No problem Karl.
You may also want to have a quick read through my website migration checklist if you haven’t already done so. Although it’s not necessarily written with website merging in mind but many of the checks will be applicable.
https://www.highposition.com/blog/the-website-re-launch-seo-checklist/
Let me know if you need any help.
Chris
Thank you
Hi, just came across this as i’m trying to do export a list of URLs indexed for a site i’m working on…. We developed a way to read and strip the results that come back, giving us a list for 100 results, we then tweak the url for page 2, 3 etc…
However, there is a problem…. If you look at the results for any site with a large number of page (www.bbc.co.uk) for example, it comes back saying 14 million results, but when you start to page through them, you can only get to page 5, so the first 500 results…
Has anyone else experienced this - or does anyone else know how to page through the entire results set for a site: search in Google?
Thanks
Beautiful tutorial. Exactly the tools I needed
Thanks Greg, glad you found it useful
great too - thanks!
I am looking for a similar tool which strips the Google image search - any ideas? Or maybe you could build one?
Hi David,
What would you be stripping from Google Image Search exactly? The image URLs or the images themselves?
Chris
The URLs…. when I search for a keyword in image search, I can only see the images and there is no easy way to see if “my” domain is listed… (have to mouse over).
So it would be great to show a list of all the ranking article-URLs (and/or and list of the ranking image-URLs)….
David your wish is my command. Try this tool which should hopefully do the job for you. Let me know how you get on!
Hey Chris,
First of all, thanks for sharing such detailed and valuable tutorial for us web masters.
I came across this blog post a while ago. I followed the step by step tutorial and it worked fine at first, until I came to step 5. I could not get what you showed in your situation. Well…it could be like what you said, Google keeps tweaking the way SERPS are displayed. What works in most scenarios might not work in certain ones.
After spending some time on this, I end up with figuring out another solution that works perfectly for me to extract URL list indexed by Google. And I wrote this article http://www.baunfire.com/tactical-blog/extract-site-urls-google-search-results.
Hope it is somewhat helpful to your readers.
Best,
Jiangpeng
Hi Jiangpeng,
Thanks for the comment and for sharing your post.
Indeed Google changing the code behind the layout of SERPs in a issue for tools like this which rely on class names etc, but I’ve tweak the tool several times now and it should work OK…for the time being at least.
Can you provide any further detail about the problem(s) which you are experiencing? If so I’ll try to help resolve any issues.
Whilst your tutorial will work, the problem with your approach is that it limits results to 100. One of the main purposes of this tutorial is to use the extraction tool alongside gInfinity to remove the need for multiple search queries, thus making the process quick and easy. The need to perform multiple queries (as per your tutorial) inevitably increases the risk of error.
Thanks for sharing though, and I look forward to hearing from you again regarding your issue.
Chris
Hello Chris,
Many thanks for sharing such a nice article.
It is very helpful to the readers like us.
I am trying to use the concept for extracting the Indexed URLs.
The process is very quick and easy..
Regards
Martin
Could you help me understand possible reasons as to why tools like this would suggest i have 63 urls indexed and yet google webmaster tools index status, suggest i have 70. We are coming to the end of a deindexation process of many pages, could webmaster tools data simply be a couple of weeks behind the search results?
Hi Roger,
In my experience the count of indexed pages within Google Webmaster Tools is the most accurate reflection of the number of indexed URLs you’ll get.
The problem usually resides with the site search operator which does not necessarily return all pages indexed by Google.
There could be a number of reasons for this but one common reason is because results sometimes reside within Google’s supplemental index and are therefore excluded from initial set of site search results.
I’ve said for a number year that Google Webmaster Tools should allow you to see which URLs are indexed rather than just providing the number of indexed URLs. That would be a much more useful tool.
I hope that helps.
Chris
Hi,
nice trick, however it doesn’t work when there are html tags in one of the URLs or Titles. I did fix it, see here : pastebin.com/JfRPn8yL
Hi Chris -
Many thanks for this - really useful, especially your SERP URL listing tool.
Wizard!
This is coming in really handy working to remove a bunch of spam urls created by an invading hacker for my client’s website. Filthy stuff… We got the site cleaned up and the manual penalty removed, but these hideous urls are still showing up in the SERP, like swamp gas bubbling up from the muck of the index. They’re still surfacing at varying rates, from 3-50 per day.
I’m using a keystroke macro to enter the daily url removal list into Google’s removal tool.
Your method is saving me a lot of time and increasing my rate of return on time spent! I’ve flat-rated each url…
Maybe someday Google will relent and provide CSV upload capability? Feature request time.
Fantastic! Wow, this helped me a lot!
A bit complex but worked well for me. Once you understand how it works, quite easy to do it next time. Love this though.
Hey I tried this and this bookmarklet is only fetching 551 Url and Anchors from google’s index of 3500. Is there any fix for that for possibly getting all the pages?
Hi!
Thanks for this tutorial.
I need a list of all my url’s to redirect them to my new website.
However isn’t much easier to get a list of all the url’s from Google analytics?
In Google analytics go to:
Behaviour => Site content => All pages
The last part of that page contains a table with all urls and below on the right is a selection box, where you can expand all output to up to 5000 lines.
Above is a link “export” with lots of options like csv.
Or am I missing something?
Gr.!
Bob
hi matt, It’s a good tools. do you have a bookmarklet that will extract just the description from google SERP ?
thanks, before
Hi Chris,
Thanks for sharing. I am stuck on the step 5.
How do I export the SERP from Google?
Many thanks.
Dorian