Picture this - you’ve spent what seems like forever planning the design and build of an all singing all dancing website. You’ve built your shiny new website covering all possible on-page SEO factors to ensure your website is uber search compliant; but when you launch the website it all goes horribly, horribly wrong with organic search rankings taking a nose-dive and organic search traffic declining rapidly. No one wants to be in that situation!
I’ve been in this business for many years now and lost count of the number of times I’ve seen (or read about) websites which have suffered severely following the poorly managed launch of a new website. Sometimes it happens because the website has been built incorrectly or inadequately; but more often than not it’s because website launch procedures have not been suitably planned.
In this tutorial I’ll walk you through the important techniques which you can use at the website launch phase to ensure you maintain as much organic search traffic and ranking as possible. I’m assuming you’re re-launching a website rather than launching a website for the first time, but there will probably be some cross-over.
Pre-Requisites
1. On-Page SEO Factors
I’m assuming you’ve already done your homework, brushed up on your practical SEO knowledge and taken care of all the important on-page SEO factors relevant to your build - correct? This includes basic factors such as implementation of sufficient content and unique Titles/headings through to complex factors such duplication management techniques and implementation of structured data.
There are way too many considerations to list in this post, considerations which vary depending on your build, so if you’re unsure you might want to read through my ultimate CMS wish list. This may help to identify important build considerations which may transfer to your specific build.
2. Website Benchmark
How can you gauge the impact of your new website if you don’t understand the performance of your old website, right? At minimum you should have an understanding of
- Organic search rankings:
You need the ability to track movements within organic search. Whether you do this manually or through a rank monitoring system this data is vital.
- Average monthly search traffic:
To gauge the impact of the new website in relation to search traffic it’s important to understand traffic statistics. It’s also worth understanding current/nearby seasonal trends and other important statistics which may be mistakenly confused with the impact of site launch.
You may also wish to benchmark Google’s index statistics and the website RageRank and/or Domain Authority although I would not deem this as important as the two points above.
Website Launch Recommendations
So onto the website launch recommendations for SEO which you should consider when launching your new website. Hopefully there are a couple of factors here which you’ve already addressed during the design and build phase(s). I’ve pulled the list into a rough outline of priority but in reality all are important recommendations.
1. Google Analytics Tracking Code
I’m sure you will have covered this pre-launch, but it’s worth taking the time to double check that your Google Analytics tracking code is present on all required pages throughout the website or if you’re using an alternative web analytics package ensure it’s configured to record web traffic.
Here’s a quick crash course in basic checking of Google Analytics tracking code installation using Screaming Frog. If you’re not using Screaming Frog I’d recommend you get hold of it - it’s a very handy tool.
- Ensure you have your Google Analytics UA ID to hand - You can find this through the Account Setting within the Admin section of your Google Analytics account
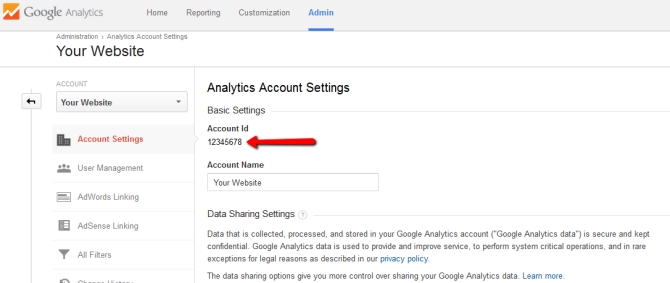
Alternatively you’ll find it within the source code of your website. - Open Screaming Frog
- Enter the URL to spider
- Click the Configuration menu and go to Custom
- Enter two filters, one which ‘Contains’ your UA number and one which ‘Does Not Contain’ the UA number.
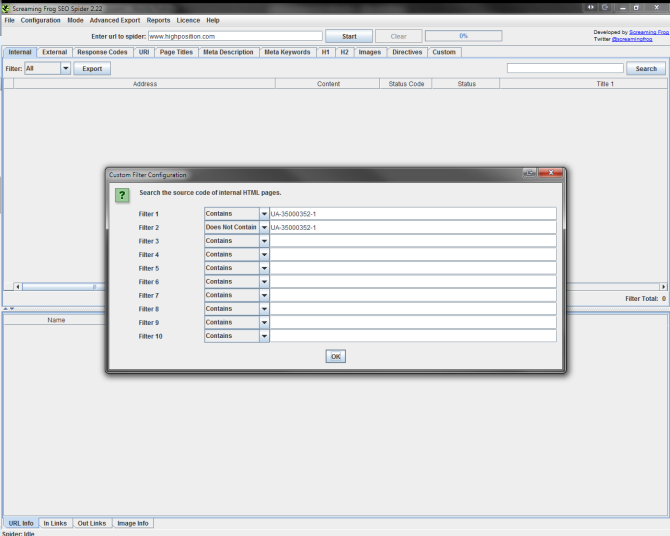
- Start the crawl and wait for it to complete.
- Click on the Custom Tab, and use the Filter dropdown to switch between your filters
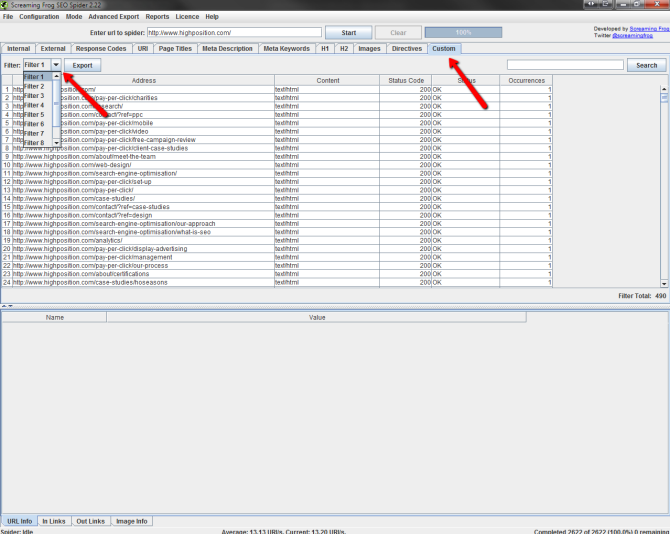
If you’ve configured the crawl following these instructions you should be able to use Filter 1 to see all pages with the tracking code installed correctly, and Filter 2 to see all pages which do not include the tracking code. You can then export the data, filter it, and use it as you wish, but make sure you address the pages which do not contain the tracking code unless there are relevant reasons not to do so.
2. Webmaster Tools Validation
It’s not uncommon to overlook the accidental deletion of the Webmaster Tools verification tag or file following the launch of a new website. Whilst this isn’t the end of the world and won’t affect organic search traffic or ranking, Webmaster Tools does contain lots of valuable post-launch data so it’s important to retain access.
I’m not just referring to Google Webmaster Tools either; Bing Webmaster Tools has seen a lot of improvements recently and should not be overlooked.
If you’re launching on an existing domain, ensure the Webmaster Tools verification tag/file is carried over to the new site to avoid any temporary access loss. Alternatively if you’re migrating the website to a new domain ensure you configure Webmaster Tools for the new domain prior to website launch if possible or upon launch.
3. Check for Accidental Crawl Restrictions
Now you’ve ensured you’ve got access to the required data it’s time to check you’re not accidentally restricting access to the website.
This is no joke and arguably the most important launch factor. On too many occasions I’ve seen websites launch with crawl restrictions in place and watched in awe as rankings and traffic decline rapidly.
Here are some of the steps which you should take to ensure the website remains accessible to search engine spiders:
- Check robots.txt directives have been removed correctly
- Check any noindex,nofollow directives have been removed correctly
- Check any password protection have been removed or disabled
- Perform Fetch As Googlebot on various URLs through Google Webmaster Tools to ensure URLs are crawlable
- Perform Fetch As Bingbot on various URLs through Bing Webmaster Tools to ensure URLs are crawlable
Likewise it’s worth checking at this stage that your development server is not accessible to search engine spiders to minimise any potential duplication. Hopefully this has been considered already throughout the build process, but if not, then now is the time!
4. Redirect Strategy
If checking the status of potential crawl restrictions is not the most important website launch factor then the redirect strategy most certainly is! I cannot stress enough how important this is to help maintain organic search rankings and traffic through organic search.
“If you need to change the URL of a page as it is shown in search engine results, we recommend that you use a server-side 301 redirect. This is the best way to ensure that users and search engines are directed to the correct page. The 301 status code means that a page has permanently moved to a new location.” - Google
To put it simply, if the URLs within your new website differ to the URLs in your old website, be it a change to the core structure of the URL or due to migration to a new domain you must tell search engines about the change.

I’ve seen many website launches suffer due to lack of redirects. I’ve seen instances of recovery if a redirect strategy is deployed rapidly. I’ve also seen permanent damage when the problem has been identified too late or not at all!
This is one of those recommendations which I hope you’ve thoroughly planned prior to launch, but it’s often a phase which is overlooked, and even the best laid plans can fall by the wayside; so let’s cover some of the basics when it comes to redirection strategy.
Like-For-Like Redirects
Ideally all URLs should redirect on a like-for-like basis, meaning that each individual URL from the old website should correctly redirect to the corresponding URL on the new website. For small websites this is often a fairly straightforward process but for larger websites, especially e-commerce websites, this can often be a complex and time consuming (often manual) process.
The redirection strategy will inevitably depend on your specific needs. It may be possible to pattern match URLs if there are commonalities between the old and new URL structures to help simplify the process. Otherwise it may be a case of manually mapping each URL.
This can often be a very tedious process, especially if managed manually but it’ll pay dividends in the long-term.
Top Content Page Redirection
If it’s simply not feasible to map all URLs on a like-for-like basis you’ll need to identify an alternative redirect strategy.
A common alternative is to use the historical Site Content data within Google Analytics data to identify which pages are likely to require redirection.
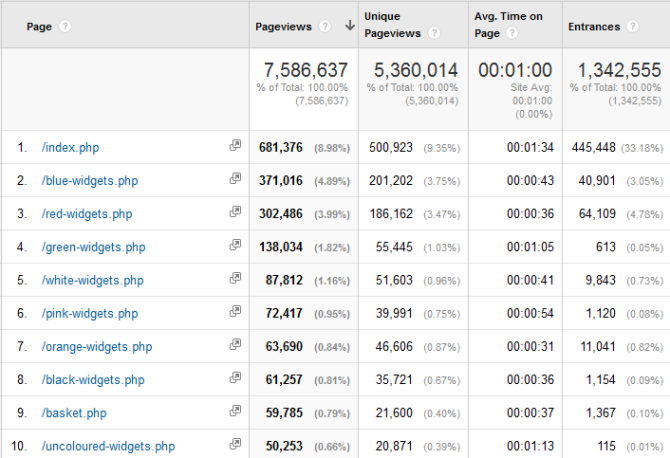
You can use the content reports to establish which pages acquire the most:
- Visits
- Pageviews
- Entrances
- Most time on site
- Highest level of conversion
- Highest e-commerce (and/or goal) value
Or any other such statistics allowing you to determine which pages are significantly important to the website and require redirection.
I would recommend ensuring you use a relatively large time-frame, perhaps reviewing content data for the past 12-18 months to ensure you have an accurate view of the data available.
With this approach you may need to anticipate a level of ranking or traffic loss for any URLs not redirected as part of the strategy and have a backup plan to compensate for this loss, such as increased Paid Search budget.
NB: However you plan your redirect strategy; ensure you have a list of originating URLs and their corresponding destination URLs for use post-launch.
What to do With URLs Which No Longer Exist?
A common question people often ask is how to handle URLs for pages, product or services which do not exist on the new website.
Google’s Matt Cutts recently addressed a very similar question in a Google Webmasters video.
This is often an area of contention between SEO’s with various views on what is the right or wrong approach. For me, I always try to approach it from a user’s perspective.
On smaller sites I tend to follow the same approach as Mr Cutts mentioned whereby you should consider continuing to serve the original landing page but clearly state that the product is not available, guiding the user towards relevant alternatives.
On larger websites with a higher URL mortality it needs to be handled on a case-by-case basis. If there is a relevant alternative available which is beneficial to the user (perhaps the same product in a different colour or size?) then redirection is a safe method.
If there are no relevant alternative landing pages then redirection, in my opinion, is not valid. It’s not beneficial to a user to redirect them to an irrelevant page; it’s confusing and often very frustrating for the user, so don’t do it.
People often ask if non-existent URLs should be redirected to the parent category/service page? In my opinion this is acceptable on a small scale, but for larger websites it’s not necessarily viable. If you do opt for this approach then ensure your category pages provide an adequate route to similar products.
In any event I’d recommend ensuring your website utilises an internal search function as this is often the fallback mechanism for users who cannot find what they are looking for. This may just be you saviour from increased bounce rate on 404 errors.
Ensuring You Have all URLs Indexed by Search Engines
Knowing that you’ve configured redirect for all URLs indexed by search engines is difficult. Both Google and Bing Webmaster Tools have features which allow you to see the number of pages indexed, Bing even allows you to see which pages are indexed through their Index Explorer; yet neither platform allow you to download a list of the URLs indexed.
I do have a (somewhat sneaky) tactic for acquiring a list of URLs indexed by search engines which I will cover at a later date. In the meantime ensure you do your best to cover all URLs which you’re aware of and be on the lookout for 404 errors following the launch.
Update: I’ve written a quick guide to extract a list of website URLs indexed by Google which you can use to help generate a list of URLs.
Ensure the Redirects are Deployed
As I said previously, even the best laid plans can fall by the wayside so you’ll need to be confident that your redirects have been correctly deployed upon launch.
The simplest way to check the redirect status is to crawl the old URLs and check to see if they redirect accordingly. This is where the aforementioned URL redirect list comes into play.
With Screaming Frog this process is pretty simply, so here’s a quick crash course…
- Save your list of original (old website) URLs in a .txt file
- Open Screaming Frog
- Select the ‘Mode’ menu and choose ‘List’
- Click the ‘Select File’ button and locate your .txt file
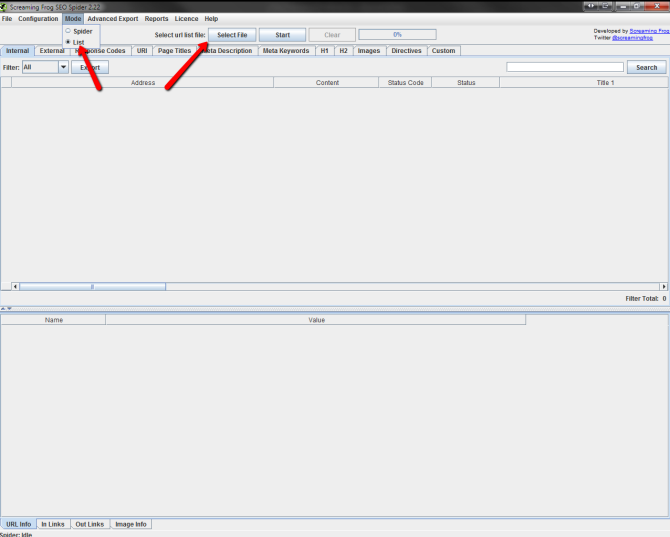
- Ensure the number of URLs imported is correct
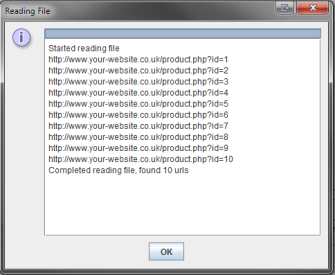
- Click ‘Start’ and wait for the crawl to complete
- Click the ‘Response Codes’ tab
- Review the ‘Status Code’, ‘Status’ and ‘Redirect URI’ columns to look for any inaccuracies
If required you can export the data to CSV and filter accordingly. If you’re Excel savvy you could also run vlookups on the Redirect URI against your redirect list to check inaccuracies – it’s actually quite easy to do!
Change of Domain Protocol
In addition to standard methods of redirection, if you’re migrating to a new domain you should initiate the change of domain protocol. Both Google and Bing Webmaster Tools have similar protocols to allow webmasters to inform the search engine about the domain migration.
In Google Webmaster Tools the protocol is known as the Change of Address protocol available via the settings gear icon - more information can be found here - https://support.google.com/webmasters/answer/83106?hl=en
In Bing Webmaster Tools the protocol is known as the Site Move protocol available through the Diagnostics & Tools section - more information can be found here - http://www.bing.com/webmaster/help/how-to-use-the-site-move-tool-bb8f5112
Inbound Link Change Requests
Sometime I’m asked whether it’s worth performing a review of inbound links and contacting webmasters to request a change of URL – a very good question indeed.
Theoretically configuration of 301 redirects should be an adequate procedure to ensure any link equity is correctly passed to the new destination URL. So you shouldn’t need to worry too much about requesting link changes.
That said, you may wish to review any inbound links from high profile domains. There’s definitely no harm in contacting the webmasters, notifying them of the change of URL, informing them that you’ve handled the move through redirection but kindly requesting that they update their hyperlink(s) to maintain consistency.
5. Replace/Submit Your XML Sitemap
So you’ve handled your redirects accordingly which is great, but you may also inform search engines directly of your new URLs through the submission of an XML sitemap. Both Google and Bing Webmaster Tools have the facility to submit an XML sitemap so make sure you’re making use of this feature.
If your CMS does not automatically generate an XML sitemap then there are various tools available to achieve this.
I know I’ve mentioned Screaming Frog several times (I swear I’m not a Screaming Frog salesman!) but it’s a powerful piece of software which coincidentally is also capable of XML sitemap generation! That said, you need to be careful as Screaming Frog will output an XML list of all URLs provided; including any URLs which have been canonicalised. Therefore it’s worth double checking the XML sitemap prior to submission.
6. Canonical Tag Sanity Checking
Duplication management through canonical tags can be a great way to minimise duplication, but if implemented incorrectly it can be catastrophic. Don’t believe me? Check out this Moz experiment by Dr Pete to see how catastrophic incorrect canonicalization can be!
A common issue which often arises post launch is the canonical tag pointing to the development server rather than the live server (#fail!) the results of which can be devastating; so as a precautionary measure it’s worth checking the implementation of canonical tags post-launch to ensure they have been configured correctly.
And of course, Screaming Frog can help with that! Seriously, Dan Sharp should give me shares in Screaming Frog or something for all this promotion!
If you crawl the website with Screaming Frog it will return the canonical tag for the crawled URL under the ‘Canonical Link Element 1’ column.
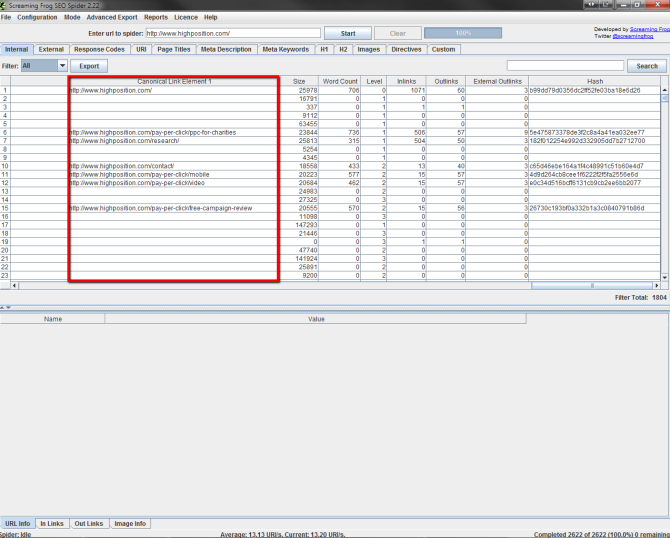
You’ll probably need to export this data and run some manual analysis to check the canonical configuration is correct; but this is a quick and easy way to obtain the data without manually reviewing the source code of each page. It’s great to highlight any critical errors.
7. Crawl Error Monitoring
You’ll also want to keep an eye on the level of crawl errors to ensure there are no drastic, or unexpected, changes in the crawl integrity.
Both Google and Bing Webmaster Tools provide various insights into crawl data so keep an eye on these metrics looking out for unexpected increases in server errors or 404 errors.
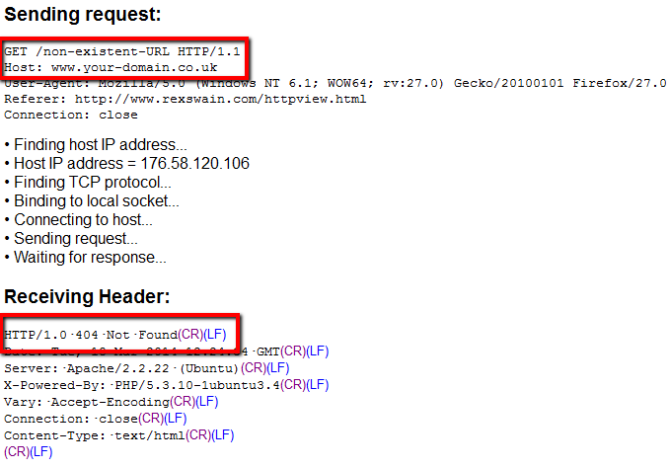
It’s also worth sanity checking your 404 error page to see if the server correctly responds with a HTTP status 404.
You can do this quickly with Rex Swain’s HTTP Viewer by entering a URL which does not exist and checking the status code:
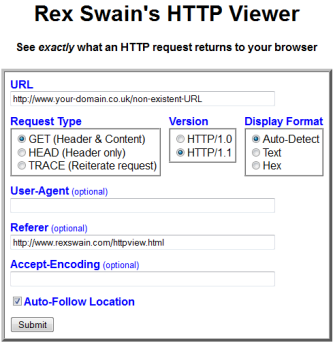
Not Directly SEO Related Recommendations
So now you’ve covered all of the recommendations which directly relate to SEO and maintaining search traffic and rankings, here are a couple of recommendations which, whilst not directly “SEO” related in the traditional sense, are extremely important to your digital marketing efforts.
1. Check Enquiry Forms and Paths to Conversion
I’m sure you will have carried out vigorous user testing prior to the launch of your new website (right?!) but you can’t be too careful.
Make sure you have a plan in place to test all methods of conversion including all enquiry forms, the checkout process if you’re running an e-commerce website, and any other paths to conversion.
2. Goal Re-Configuration & E-Commerce Tracking
With the main emphasis placed on the design and build of the new website the configuration of external tools is often overlooked. I mentioned earlier the importance of ensuring the web analytics tracking code is in place post-launch, but the configuration of goal and e-commerce tracking within Google Analytics (or your preferred web analytics package) is also all too often overlooked.
If you’ve changed your URL structure this will have a knock-on impact on your goal configurations within Google Analytics; so ensure you re-configure all goals and check e-commerce tracking to ensure you are adequately tracking conversion through the website.
3. Google Analytics Custom Alerts
Finally, Google Analytics has great, often unused, functionality to alert webmasters of important changes to traffic, conversion and other metrics.
At the start of this guide I mentioned the importance of benchmarking but that’s somewhat pointless unless you’re planning on monitoring the performance of your new website after deploying it. Whether you’re launching a new website or not it’s worthwhile configuring Google Analytics Custom Alerts to quickly highlight any changes in the performance of the website. For example, you can configure an alert to notify you when traffic falls below a certain level:
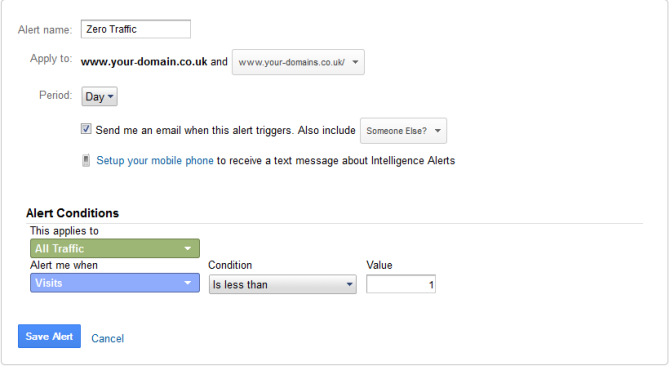
There are a wide range of alerts which you can configure, all of which will depend on your individual requirements, but it’s definitely worthwhile planning what alerts you’ll need immediately after launch and which alerts may be useful long-term.
Conclusion
So there you have it. I think that covers pretty much everything you need to consider from an SEO perspective when deploying a new website. I’ll just emphasise again that this is a launch-checklist, not a design/build checklist so make sure you’re aware of all on-page compliancy factors prior to launch.
If you think I’ve missed anything from the list please get in touch and let me know. Likewise I’d love to hear about your website launch experiences. So if you’ve got any success stories or disaster stories let us know!



